进入文件夹,git init 把这个目录变成git可以管理的仓库
1
git init
把文件添加到版本库中,使用命令 git add . 添加到暂存区里面去,不要忘记后面的小数点“.”,意为添加文件夹下的所有文件
1
git add .
用命令 git commit告诉Git,把文件提交到仓库。引号内为提交说明
1
git commit -m 'first version'
关联到远程库
1
git remote add origin https://github.com/reponame.git
把本地库的内容推送到远程,使用 git push命令,实际上是把当前分支master推送到远程。执行此命令后会要求输入用户名、密码,验证通过后即开始上传。
1
git push -u origin master
舞曲
几段喜欢的音乐,如有侵权,请随时通知。
-
“哦嘛哩嘛嘞,邦邦”
简单欢快,不知道是哪个国家舞蹈。 -
快板、慢板、快板三段,中间慢板最美,柔中带刚,刚中带柔,有一种飘来飘去的感觉。
一直没搞清楚奔腾的到底是骏马?还是套马的汉子? -
也算是一个拉丁舞种。
-
改编自腾格尔的歌曲,刘福洋和万玛尖措表演,表达两兄弟来开草原时恋恋不舍的内心。
-
探戈。
作为一个节奏控,跑步必须有鼓点,要不就跑不起来。下面几个蒙古神曲,伴我每天跑过5km
Nimble scheduler
Nimble controller 的Scheduler是由一个32K的timer来驱动的,一个tick是30.52us,完全执行在timer的isr里,所以timer callback里要做的事情不能太耗时(超过一个tick),否则scheduler就不准确了,如下为scheduler的主函数:1
2/* Initialize cputimer for the scheduler */
os_cputime_timer_init(&g_ble_ll_sched_timer, ble_ll_sched_run, NULL);
时间单位
- Tick:由clock决定,对于32K clock来说,一个tick就是 1000000us/(32*1024) = 30.52us.
- Slot:1250个毫秒
- Period:N * Slot,N是可配置的
- Epoch:M * Period,M是可配置的
Scheduler在调度的时候,有时要将Connection event放在Period的边界,scanning/initiating/advertising是尽可能发生在没有被用到的Period内。1
2
3/* Time per BLE scheduler slot */
#define BLE_LL_SCHED_USECS_PER_SLOT (1250)
#define BLE_LL_SCHED_32KHZ_TICKS_PER_SLOT (41) /* 1 tick = 30.517 usecs */
调度单位
每一个可被调度的单位叫做Sched item, 这些item放在FIFO的List中,每当timer到期后Scheduler就从List里拉一个出来做执行。
每一个item有如下几个属性:
- schedule type,类型
- enquened,是否入Q,入Q就代表是Ready,等待被执行
- remainder,剩余的执行时间
- start_time, 开始执行时间
- end_time, 结束执行时间
- cb_args, item执行函数的参数
- sched_cb, item被调度到的时候的执行函数
如下是相关的code segment
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
uint8_t sched_type;
uint8_t enqueued;
uint8_t remainder;
uint32_t start_time;
uint32_t end_time;
void *cb_arg;
sched_cb_func sched_cb;
TAILQ_ENTRY(ble_ll_sched_item) link;
};
/* Types of scheduler events */
#define BLE_LL_SCHED_TYPE_ADV (1)
#define BLE_LL_SCHED_TYPE_SCAN (2)
#define BLE_LL_SCHED_TYPE_CONN (3)
#define BLE_LL_SCHED_TYPE_AUX_SCAN (4)
#define BLE_LL_SCHED_TYPE_DTM (5)
#define BLE_LL_SCHED_TYPE_PERIODIC (6)
#define BLE_LL_SCHED_TYPE_SYNC (7)
调度原则
- Sched item之间没有优先级的关系,完全按照Sched item的start_time为序,一个一个的执行。
- 调度到某个item时就直接执行这个item的sched_cb,并将这个item从调度列表上删掉,callback执行完后,再起timer,等待下一个item的start_time到期。
- item在插入到调度列表的时候就已经排好序了。
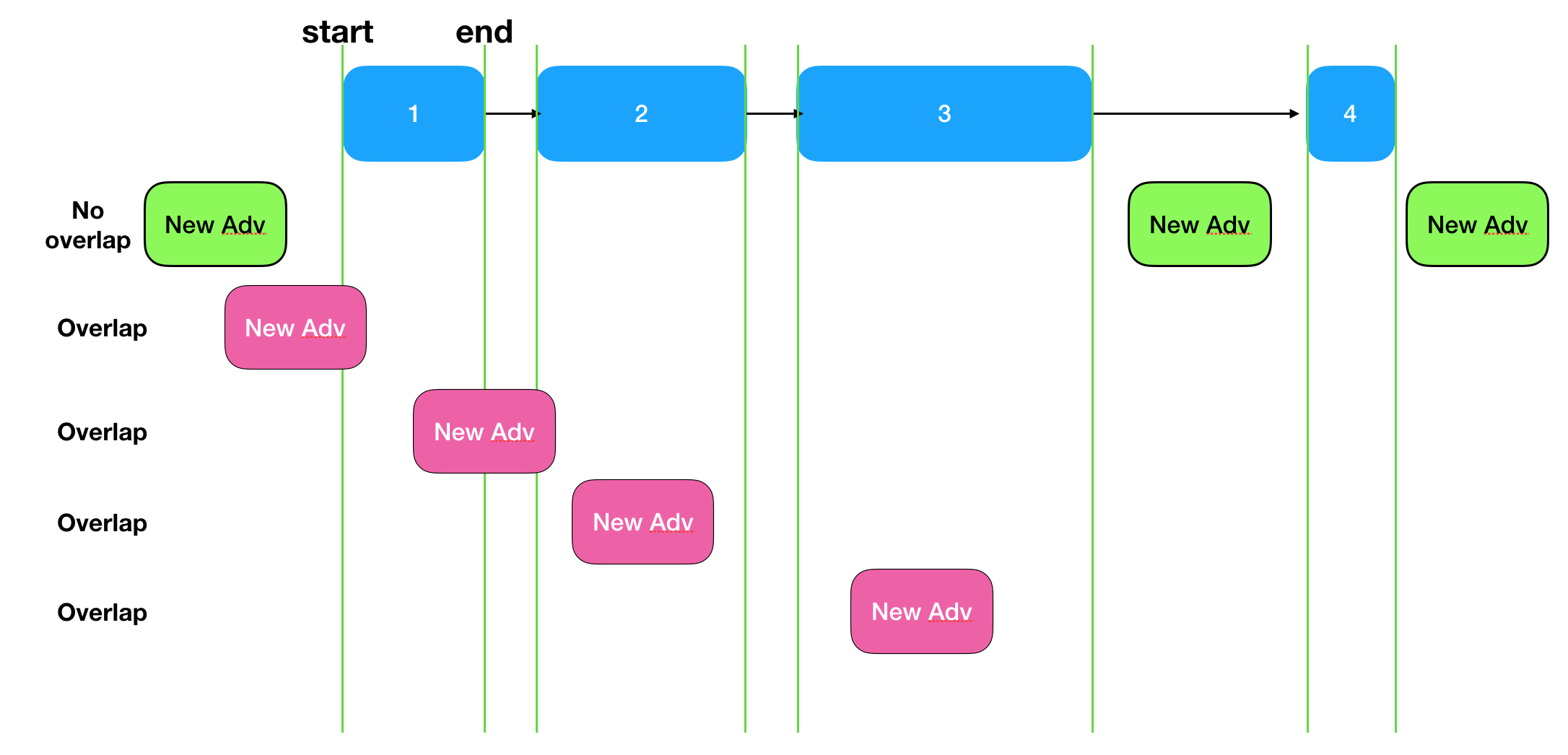
- 在插入新的Adv Sched item的时候,新的Adv要避开每一个跟他有overlap的item,直到找到一个完全跟它没有overlap的位置,这意味着在有同样的start time的情况下,先入list的优先级高。
- 以插入一个Adv Schedule为例,假如Scheduler的ReadyList里有4个item,它们的排列如下。那么下图中绿色的item就是可以直接插入的item,而红色的item则需要一直往后移动,一直移到一个能插入>的地方,也许到list最后才能有它的一席之地。
- 在一个adv event执行完成后,需要再计算下一个adv event起来的时间,请参考下图。
Item中的Delay(0~10ms)指的是这个adv event最大允许delay的时间。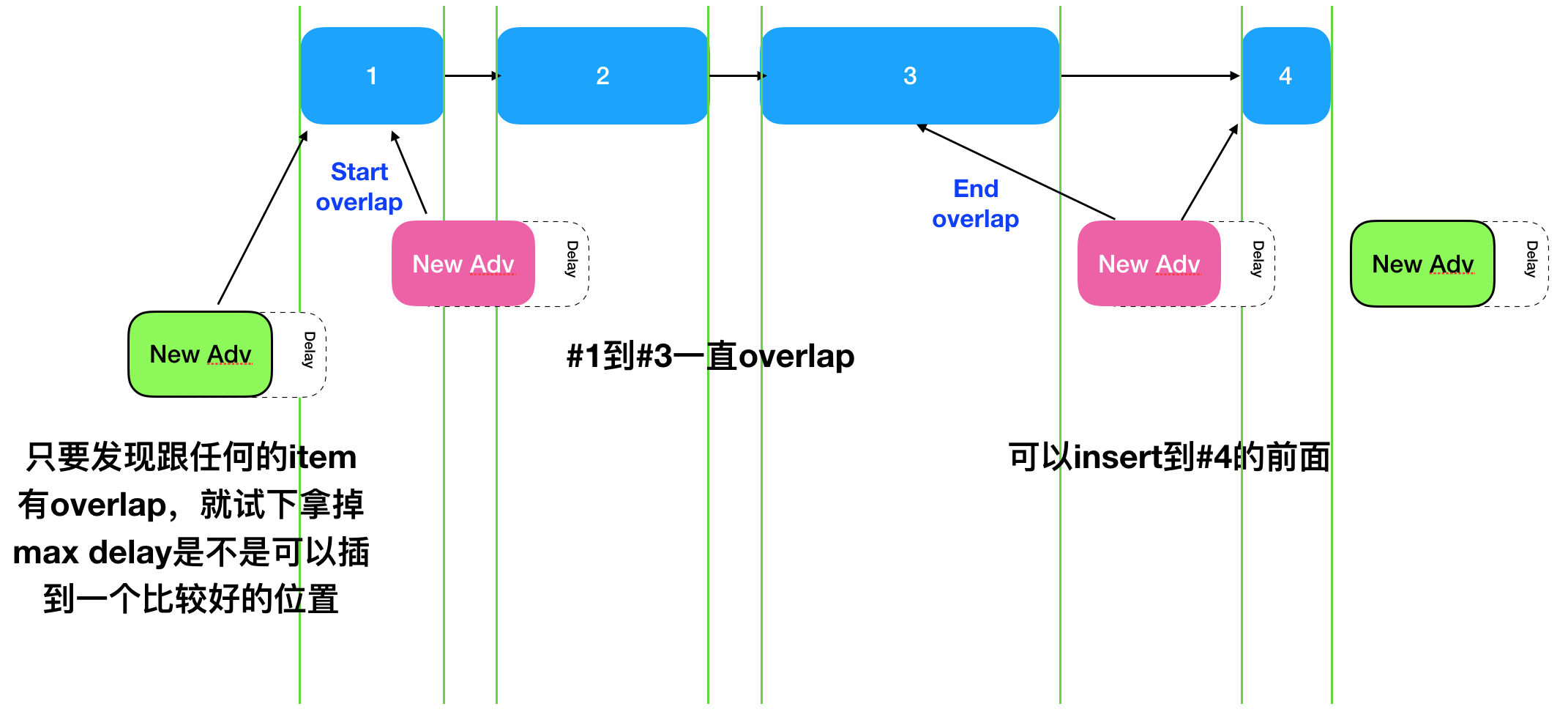
- 以插入一个Adv Schedule为例,假如Scheduler的ReadyList里有4个item,它们的排列如下。那么下图中绿色的item就是可以直接插入的item,而红色的item则需要一直往后移动,一直移到一个能插入>的地方,也许到list最后才能有它的一席之地。
- 但是对于type为CONN的Sched是有点优先级的
- 正在execute的type为CONN的Sched的优先级最高,要新建立的conn的sched (ble_ll_sched_slave_new())如果刚好跟正在execute的conn overlap,那直接就取消新的这个conn。
1
2
3
4
5/* The schedule item must occur after current running item (if any) */
if (ble_ll_sched_overlaps_current(sch)) {
OS_EXIT_CRITICAL(sr);
return rc;
}
- 正在execute的type为CONN的Sched的优先级最高,要新建立的conn的sched (ble_ll_sched_slave_new())如果刚好跟正在execute的conn overlap,那直接就取消新的这个conn。
- 在收到CONN_IND的时候,为了能尽快在windowOffset到达时发包出去回应对方,会将跟他overlap的type为CONN的sched 给盖掉
- 但这包如果type是其他的type,则会继续往后shift找合适的位置,但如果是回应CONN_IND的第一包的话,不在规定时间发包出去,link就建立不起来,这里还是有点问题。
2
3
4
5
6
/* If we overlap with a connection, we re-schedule */
if (ble_ll_sched_conn_overlap(entry)) {
break;
}
}
更正 #4
感谢jaydenh215的指导,上图中关于Adv reschedule的图例欠妥,正确的符合code行为的插入Sched的示意图如下。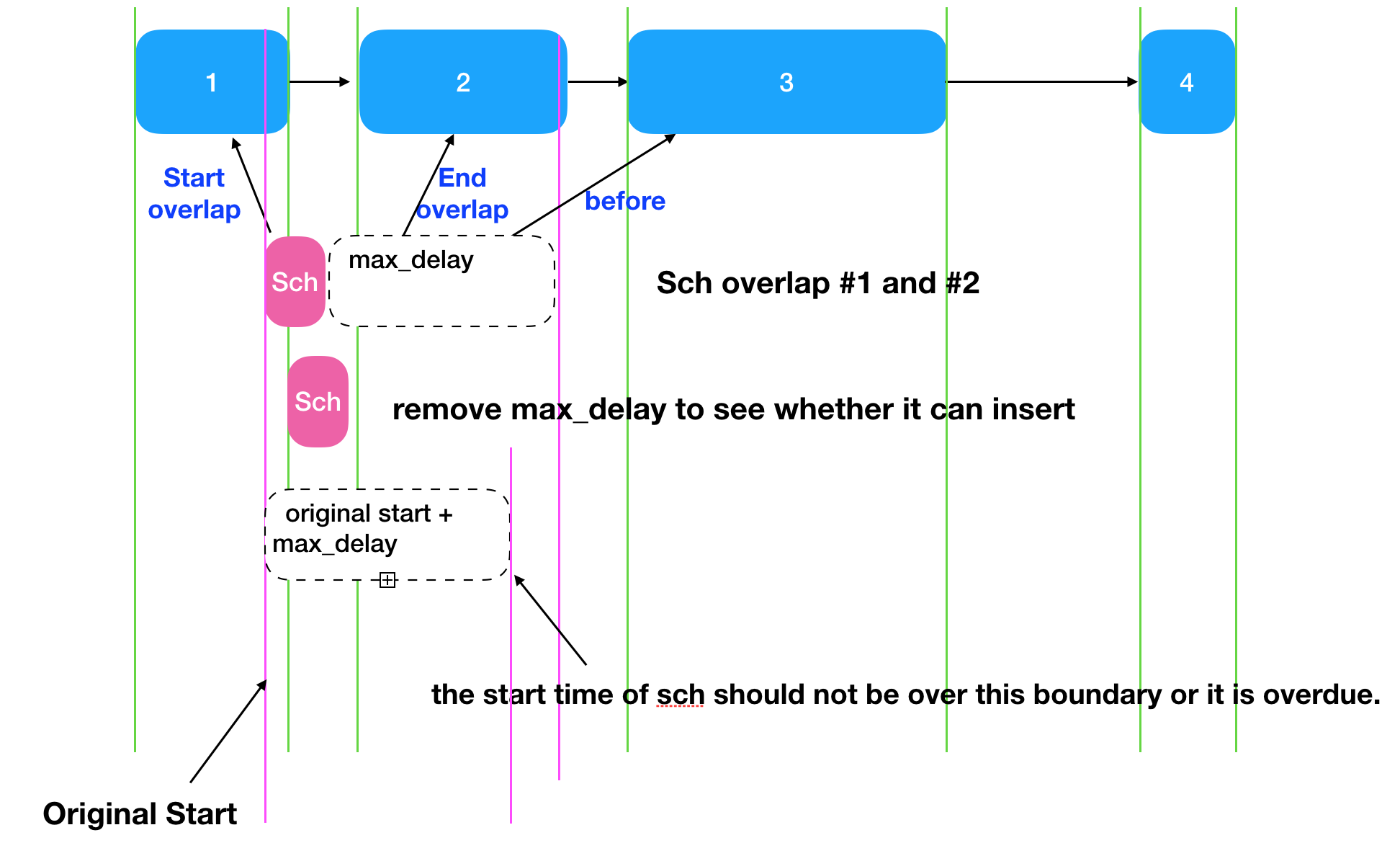
如果超过了max_delay,那插入也是失败的,如下图,虽然在#3的前面有位置给sch插入,但是因为overdue了,所以插入会失败。
阿里云使用
阿里云的主页到处都是广告,非常的花哨,如果好几天不上Aliyun,再上去很容易找不到我的文件存储服务在那里,这里先做个记录,方便日后查阅。
- 当然先做登陆,这个还是能找到的。
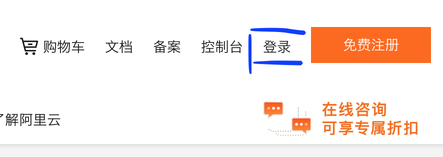
- 登陆后找这个bar,点击控制台,

- 之后进入控制台页面,寻找已开通的云产品

- 点击对象存储OSS,会进入下面的页面,下面页面里有一个“存储空间”
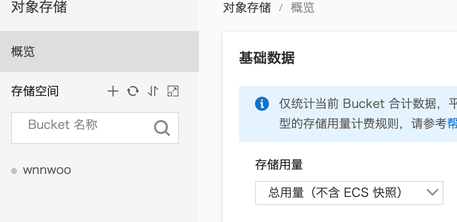
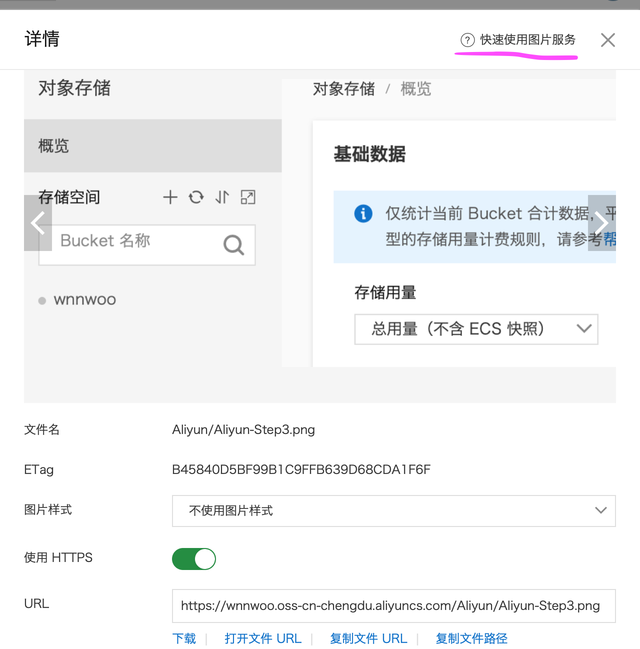
- 点击自己创建的某个Bucket,就进入了相关的存储对象的管理页面了,点击 文件管理 就可以增加或事删除文件了。

- 关于图片的处理(缩放、裁剪等等),要参考快速使用图片服务。
Periodic Advertising Sync Transfer (PAST)[未完结]
Periodic Advertising Sync Transfer 是BT 5.1的一个新feature,SIG官网上有一篇文章介绍的还不错What You Need to Know About Periodic Advertising Sync Transfer。这里就做一个简单的总结。
这个新概念的引入,本质上是为了省电。对于Legacy的advertising,Advertiser在interval附近会加一个Delay(0~10ms),那么Scanner就需要多开窗来抓到adverting 数据包,增加耗电,而PAST概念就是为了在某个场景下可以解决这个问题。
先看下几种Advertising的概念
1.Legacy Advertising
Legacy Advertising只在37/38/39三个Channel上打,为了避免adv event刚好跟Scannner的scan window完美错过,在Adv的Interval上会加一个随机值advDalay,让Anchor点随机shift一点点,增加与Scanner的scan window碰撞的几率,示意图如下:
下图为Legacy Adv的PDU的格式: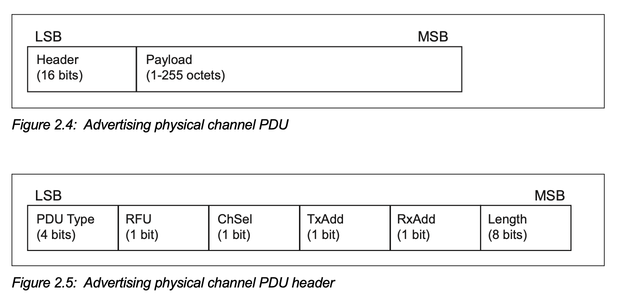
2.Extended Advertising
Legacy Advertising能发送的Adv data有限,所以后来又衍生出了 extended adv:在Data channel里也可以打Adv data,如下图。
而Extended Advertising引入的概念就比较多了,比如:
- Advertising Handle,
- Advertising Set
- Advertising Data ID
- …
当收到的Adv的type是 ADV_EXT_IND 时,Adv的Payload的数据格式如下:


3.Periodic Advertising
在Extended Advertising的基础上,在发送大量数据的时候又引入了Periodic Advertising。
Periodic Advertising 流程的建立有两种方式:
3.1 正常的Scanner 和 Advertiser的交互
如下图中AoD Transmitter 与 Smartphone的Sync。
3.2 已经有Periodic Advertising Synchronization infomation的一方,将该data通过 LE-C 转发给另外一个跟它连线的设备,就是PAST。
如下图右图中Smartphone 与Wearable Device之间的关系,Wearable device在前期不需要开Scan去抓ADV_EXT_IND就知道后续要到哪里去收AUX_SYNC_IND包,从而节约了电能。
4. 关于PAST的细节:
下图是Spec中关于Periodic Advertising的一个Sequence flow。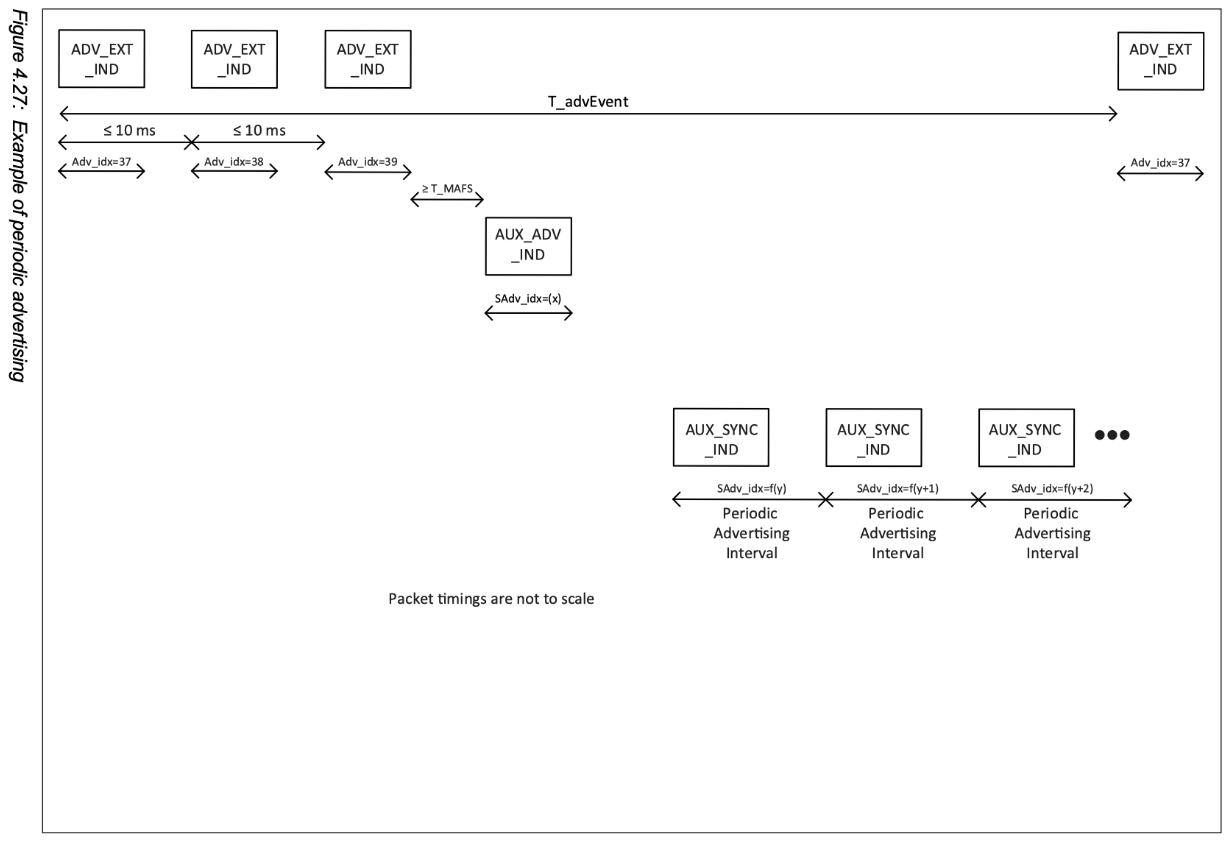
message 流程图如下:
下面三图中A是Scanner,B是Advertiser,A和B中有一个与C有BLE连线,那么会有三种情况:
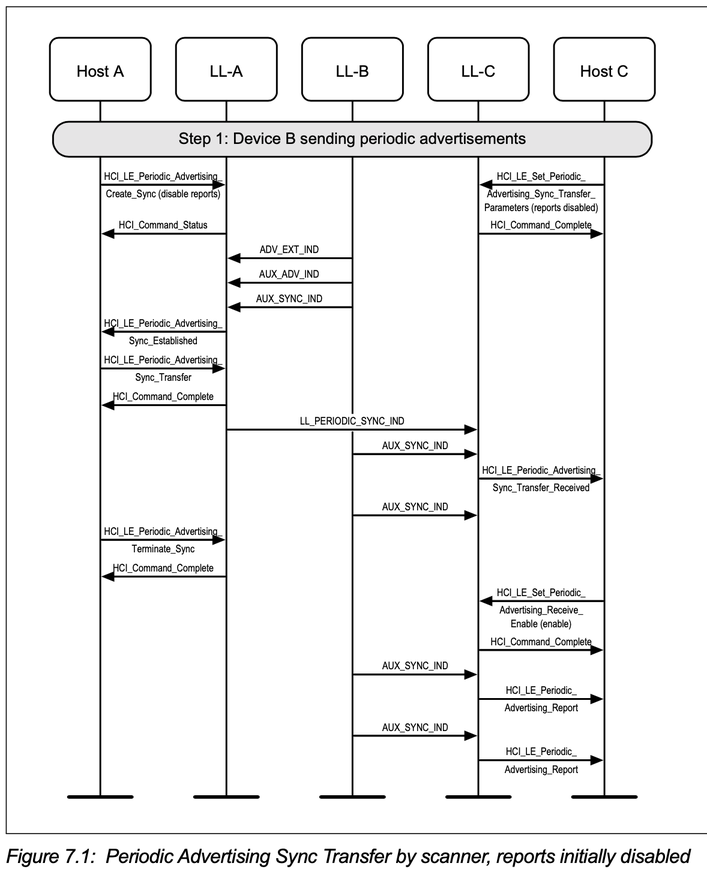
4.1 A与B建立了Sync,A与C有连线,A通过LL_PERIODIC_SYNC_IND将Sync information通知给C,那么C就可以收B的Periodic Sync advertising。
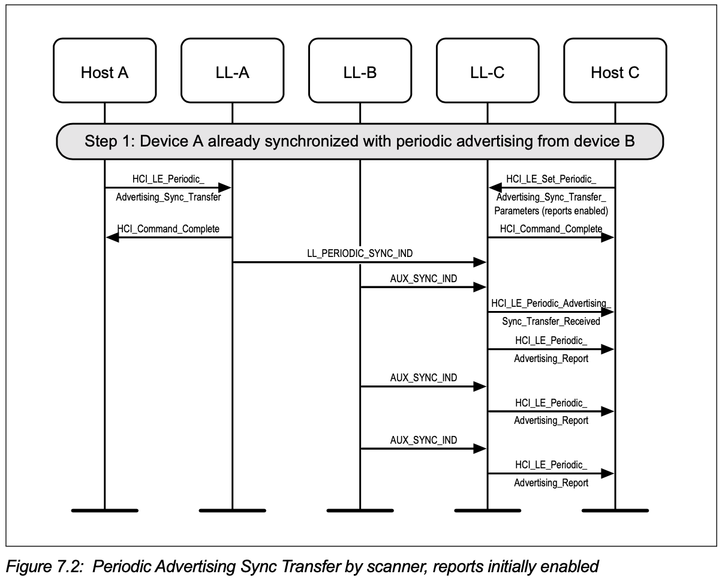
4.2 流程同4.1,只是C一开始就Enable了report.
4.3 A与B建立Sync,B与C有连线,B通过LL_PERIODIC_SYNC_IND将Sync information通知给C,那么C就可以收B的Periodic Sync Advertising data了。

做笔记的利器Marginnote
在学习的过程中经常要做些笔记,记在笔记本上的话非常不方便的查阅。如果只是记日记,记录下每天都做了啥,那用纸质的笔记本还好; 但对于学习笔记要经常整理以及归纳,就得需要经常改动及查阅。
最近有发现一款非常不错的做笔记的软件Marginnote,目前只有iOS/Mac的版本,没有Android的版本。
这款软件可以很方便的在pdf文件上做标记,并且将pdf中的关键字,句子摘录出来,制作成思维导图。让我想起了大师李敖的读书方法,李敖每读一本书,会将书拆的很碎,把经典的句子都从书上剪下来,把剪下来的句子分类整理到自己的册子里,这样自己日后在写作的时候从相关的册子里之间找自己要的东西就好了。
下图为一个处于学习模式的marginnot的snapshot:
- 总共分为三块:左边为摘录出来的文字的一个逻辑关系;中间为根据左边文字的逻辑关系生成的思维导图;右边为原文;
- 用户可以调节左边摘录文字的逻辑关系(父子关系?兄弟关系?),同时中间的思维导图也会跟着变;
- 点击左边的摘录文字,右边的原文会自动跳转到该文字所在的位置。而且这些摘录的文字可以在右边原文中选用不同的颜色。

纯时间与毛时间
第一次看到这个比较新鲜精确的概念:纯时间与毛时间
比如你说你一天上班工作的时间是8小时,但实际上只有2小时是真正在工作的,其他时间可能在做无意义的发呆或是刷微信。那这8小时就是工作的毛时间,2小时就是工作的纯时间。
这个概念是在《奇特的一生》这本书里提到的,在豆瓣上评分还挺高。作者描述了俄罗斯科学家柳比歇夫的时间统计法,用日期+事件+花费时间的方式来记录自己一天所做的事情,并坚持了56年,没有一天断过。柳比歇夫在每周,每月,每年都对自己记录的时间做总结,看哪项事件用了多久,可以精确到分钟。这样有个好处是自己对时间的估算是非常精确的。除了做总结,柳比歇夫还对自己一生的时间做五年规划,每过五年,他就把度过的时间和干过的事分析一通,可以说是做个总的鉴定,总结能客观公正的反映过去一年的历史,抓住变化无常的老想溜掉的日常生活,抓住我们没有擦觉到的损失掉的不知去向的时间。
他能准确的感知时间,精确到1分钟,对他来说,时间的急流事看得见,摸得着的,他仿佛置身于这急流之中,觉得出来光阴冷冰冰的流逝。
然而对于没有远大目标的人来说,这个方法很难坚持下去,坚持也不见得有意义。
我自己每天会做日记记录做了那几件事情,但是还没有做过总结,只是对比下去年同一天在干啥,看起来还挺有意思的。看了这本书有一种豁然开朗的感觉,原来还有记录这么细致的日记,而且对自己的时间剖析的这么认真。